
While AI news and developments are outlandish and fascinating, there's nothing quite like making something yourself! In this post, we'll learn how to code a (relatively) simple machine-learning AI that you can use to make predictions.
No machine-learning coding experience is required, but a little Python experience may help. Don't worry, though! Even if you haven't coded before, this tutorial will give you a solid understanding of the basics of machine learning. What's great about this "bare-bones" model is that it focuses more on the concepts of AI, not so much on the complicated code.
We'll be using Kaggle's Introductory machine-learning course because it provides a solid machine-learning framework. If you can access Kaggle, please navigate to the page titled "Exercise: Your First Machine Learning Model". The code should also work on any Python IDE on your computer. If this isn't possible, that's alright too!

Before we get into the code, let's briefly review how a machine-learning model works.
The most important thing to remember is that models use data to make predictions. In other words, the model churns through patterns and trends in real-world data to predict new information. Our code will import data from the internet and turn it into a usable format using a Python library called "pandas". Funny name!
Libraries in Python are like add-ons that give our code more functionality, usually in a specific field. Pandas lets us access and manipulate datasets (tables of data).

After we've imported our dataset, we want to split it into features and a target. This Kaggle course uses house data from Iowa, and our goal is to predict the price of an Iowa home based on information such as the number of rooms, size, and year built. Our dataset's features would be the columns of data we use to create predictions, while the target would be the (singular) column of data we're trying to predict! In this case, our features are the bedrooms, bathrooms, size, and year-built, columns. The target would be the column of selling price data.

Now that our data is all prepared, we're ready to create the model! We will use a Decision Tree Regressor model, which is a little less complex than others, but still tricky!
To understand how it works, let's break it down into two parts: a decision tree and a regressor. Below is an image of a decision tree.

The tree starts at the top, asking whether a house has more than two bedrooms. Depending on the answer, this tree has two options for the predicted price. In machine-learning models, the decision trees are much more complex, with many layers and outcomes.
Now onto the "regressor" part of the model. Regression, in AI, is the process of extrapolating new data points from points already given. You may have used linear regression, in which a graphing calculator or computer finds a line of best fit from a table of points.
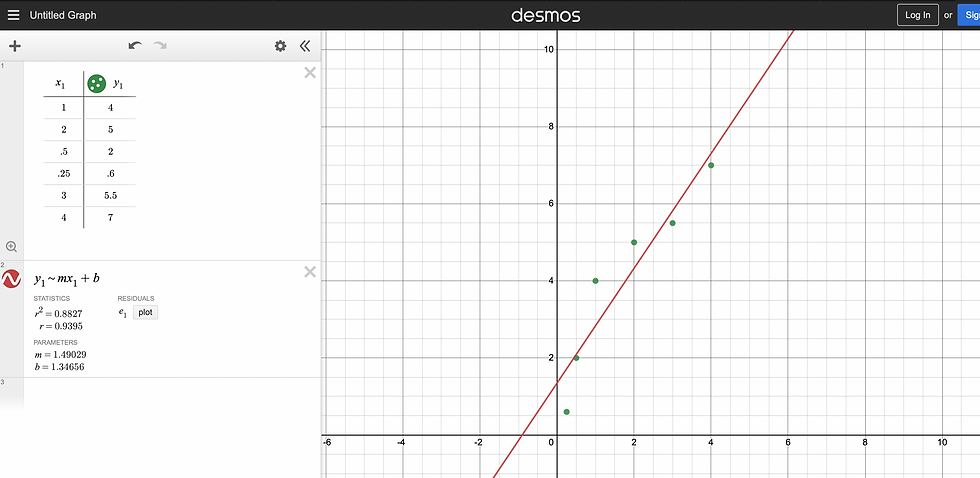
Time to put the two together! This part is a little unintuitive, so it's okay not to fully understand it. The Decision Tree Regressor model first views all of our data "points" from the dataset like points on a graph, similar to the Desmos image above. It then "splits" the graph of data points into sections, as shown in the example below.
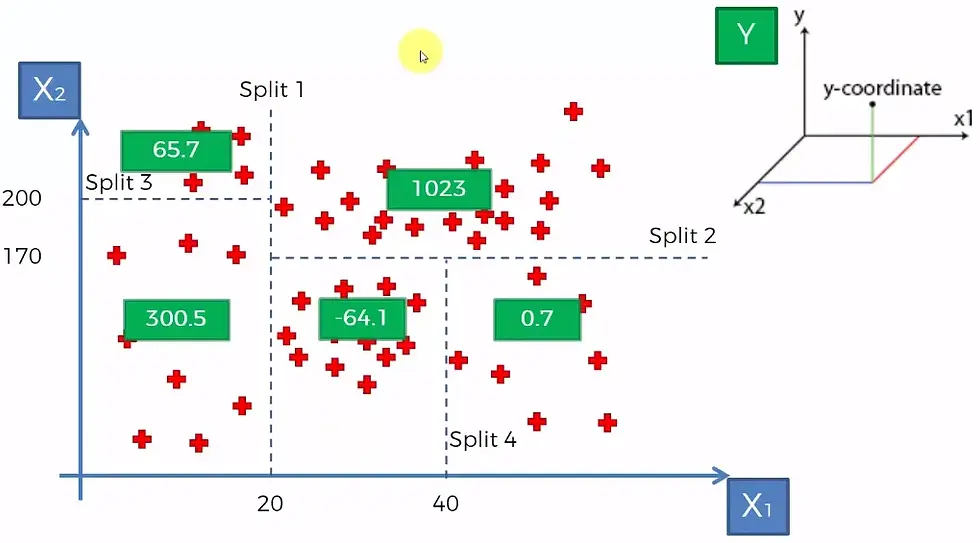
A decision tree then processes these sections of the graph, to make predictions for new data passed into the model.
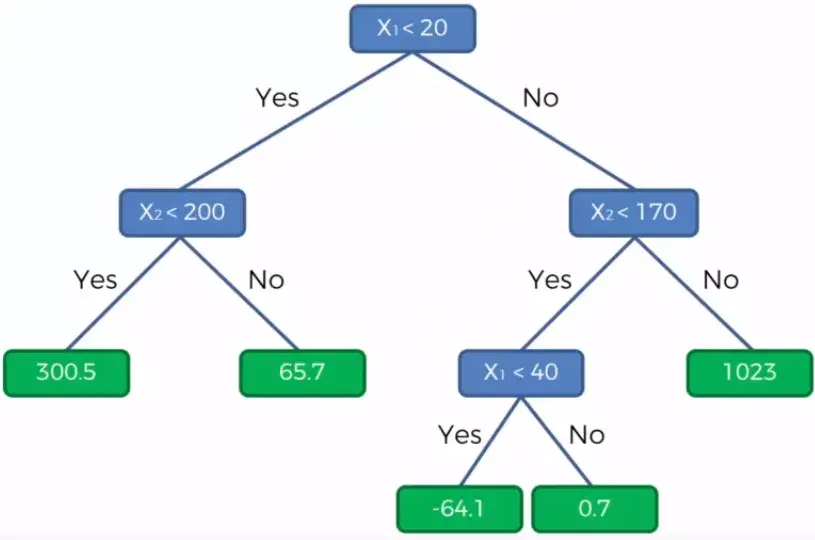
In the image above, the decision tree uses the location of the data point on the graph to determine the output for the model.
That's pretty much it! The coding should be much more straightforward now that we have covered the essentials of decision tree regressors. The code snippets in the rest of this post closely follow the order of the code in Kaggle's course, but I may omit or add some code for clarity. This post won't contain the "code checking" feature or some exercises for conciseness.
The first step is to add the pandas library to our Python code. This library lets us adjust and split datasets to make them most useful for machine learning.
import pandas as pdNext, we'll load the data from a file path, which tells the computer where to find the file of Iowa house data on our computer. We'll then assign the file path into a pandas DataFrame variable, which we'll use throughout the rest of the code.
iowa_file_path = '../input/home-data-for-ml-course/train.csv'
home_data = pd.read_csv(iowa_file_path)We imported pandas as "pd" in the previous code snippet. The statement "pd.read_csv" is a function of pandas that extracts the dataset from the file path, which can be assigned to a variable. Our DataFrame variable is called "home_data".
The next step is to make a new DataFrame containing only the feature columns. We will make a new DataFrame variable called X, a subset of feature columns taken from home_data.
X = home_data[["LotArea", "YearBuilt", "1stFlrSF", "2ndFlrSF", "FullBath","BedroomAbvGr", "TotRmsAbvGrd"]]We can change which features we use, but they affect how accurate the model will be. Usually, with fewer features, the less accurate and complex the model is. However, too many features can cause issues too!
To make another subset DataFrame with only the target column, "SalePrice", we can use a similar code snippet.
y = home_data["SalePrice"]After that, we'll initialize our Decision Tree Regressor. Using the sklearn library, we don't have to worry about the individual nodes of the decision tree, or how the regression works!
from sklearn.tree import DecisionTreeRegressor
iowa_model = DecisionTreeRegressor(random_state=42)
iowa_model.fit(X, y)We've created a variable iowa_model that contains a DecisionTreeRegressor model. The random_state parameter controls how the decision tree splits the data, but it isn't super important. I chose the number 42, but it could be any number.
We then fitted the iowa_model on the features and the target DataFrames. Our Decision Tree Regressor is graphing, splitting, and making a decision tree to later make predictions.
If we want to predict how much money a new house would sell for, we can assign the features of that one house to a variable, and use the predict function in sklearn.
newHome = pd.DataFrame([[11000, 2023, 1000, 700, 2, 4, 8]], columns = ["LotArea", "YearBuilt", "1stFlrSF", "2ndFlrSF", "FullBath","BedroomAbvGr", "TotRmsAbvGrd"])
print(iowa_model.predict(newHome))Here, the variable newHome contains feature data for a hypothetical new home. As a result of running the code, we get a prediction of $164,000.
Now that you've seen or written your first machine-learning model, you can modify whatever you like! Try changing the features, target variable, and newHome variable to see what you get!
In short:
Machine learning models use real-world data to make predictions about new situations.
Decision Tree Regressors are a type of machine-learning model that combine decision trees and regression. Regression is when a model extrapolates new data points from given points, and decision trees are when decisions are broken down into multiple nodes.
The Python libraries pandas and sklearn make machine learning straightforward. We don't need to know much about how the models work to implement them in code.
Comments